
Álvaro Martínez Flores
Data Analyst · Data Science · Machine Learning
Soy Álvaro, analista de datos orientado a transformar datos en información clara para la toma de decisiones dentro de la empresa. Me gusta trabajar con Python, SQL y Power BI, siempre con un foco en la limpieza de datos y la visualización de estos.
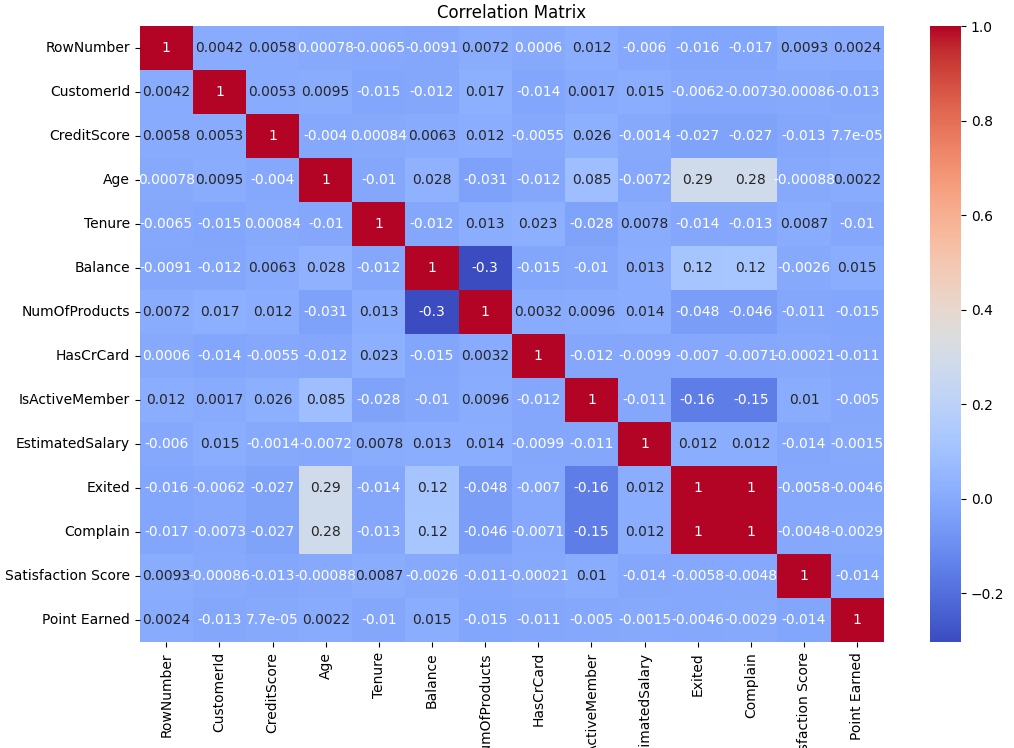
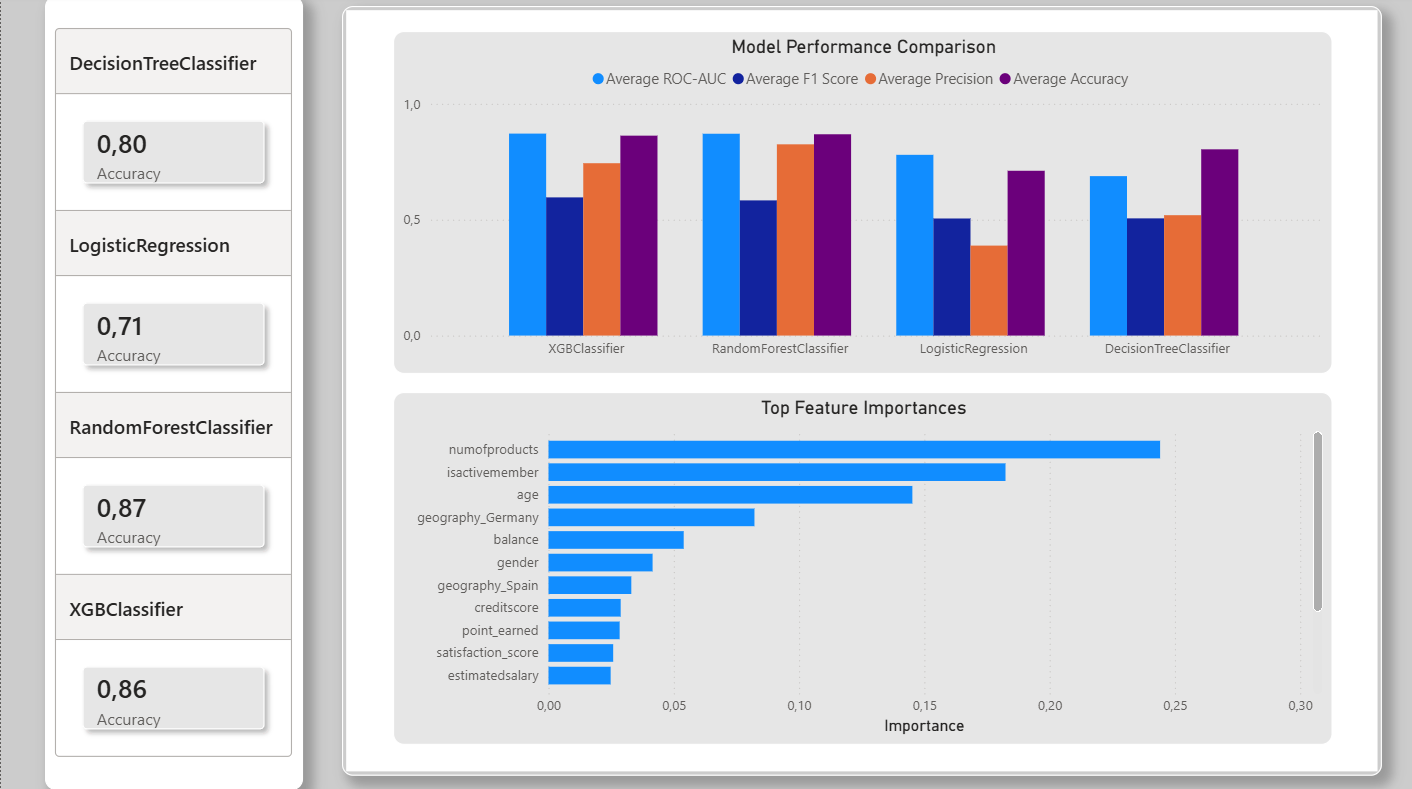
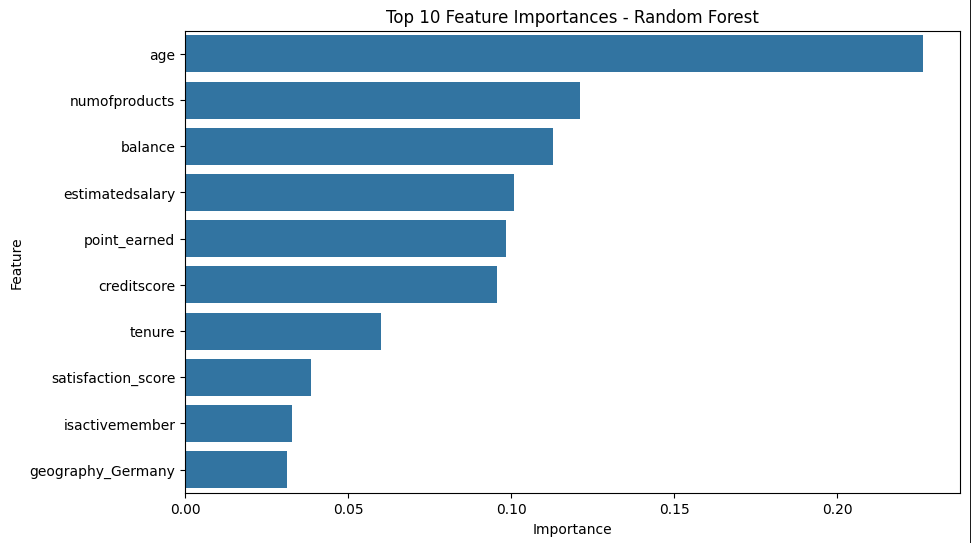
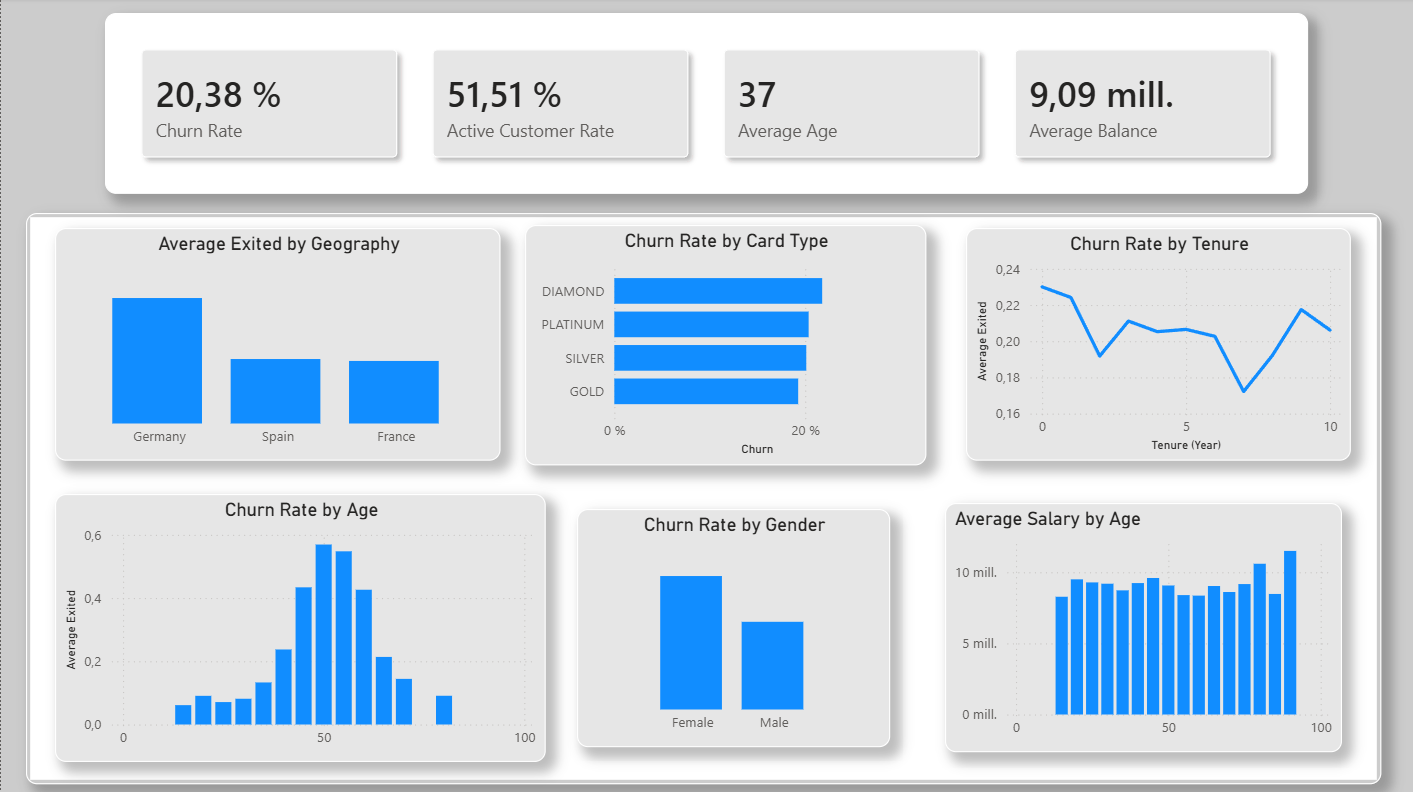
He trabajado en proyectos personales como StrikeWatch (detección de rayos en tiempo real), AireVis (análisis de calidad del aire), Excel Analytics (dashboards y limpieza de datos) y Bank Churn Prediction, un proyecto de análisis predictivo enfocado en detectar clientes con riesgo de abandono bancario.
Descargar CV
(ᓀ ᓀ)
PROYECTOS

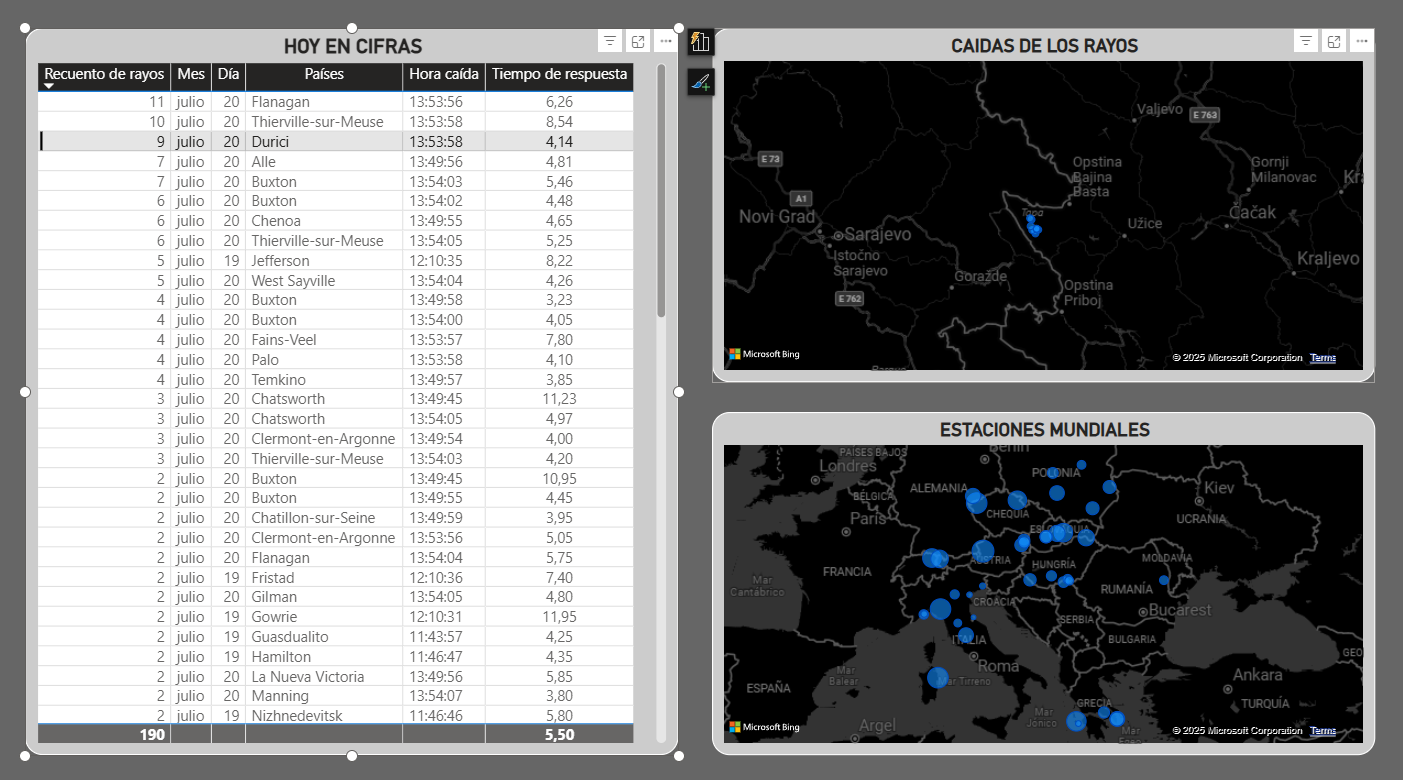
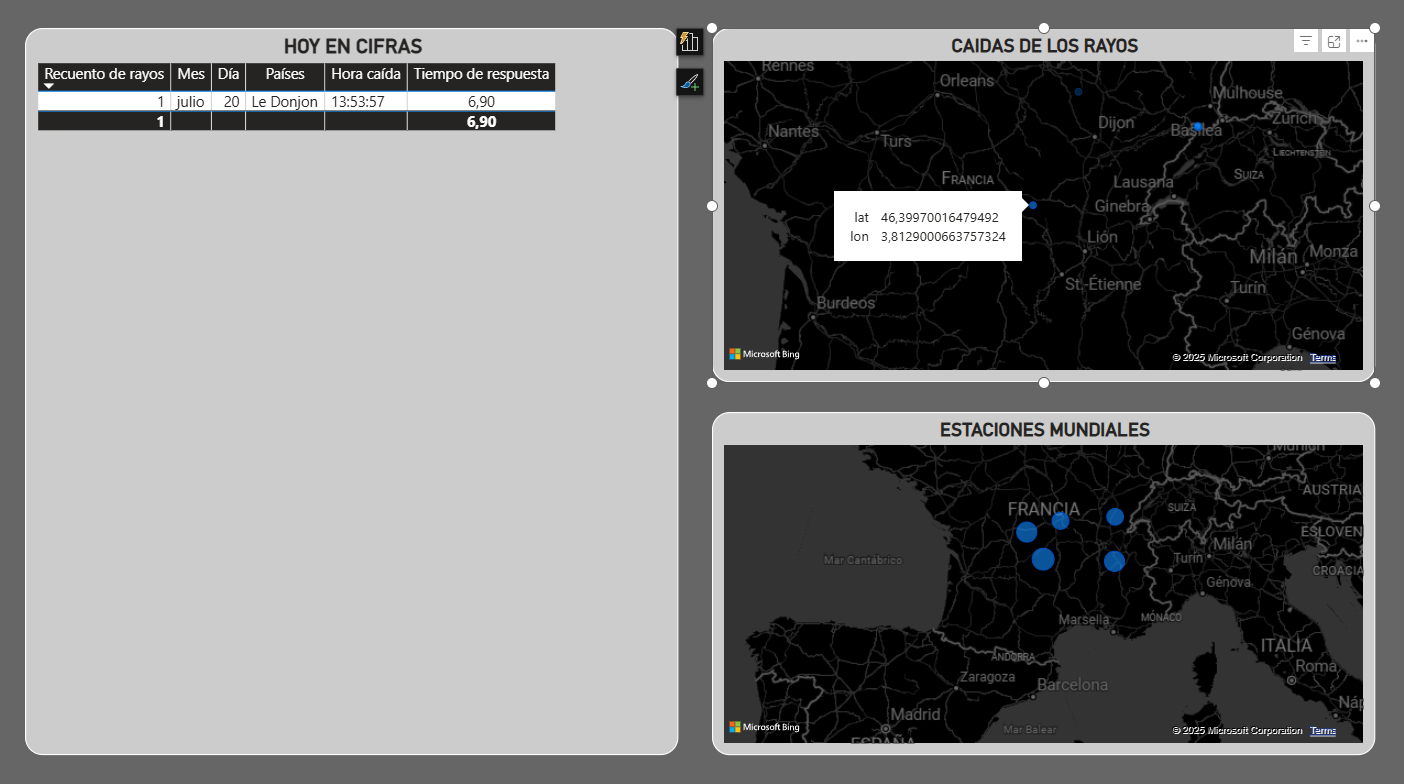
StrikeWatch
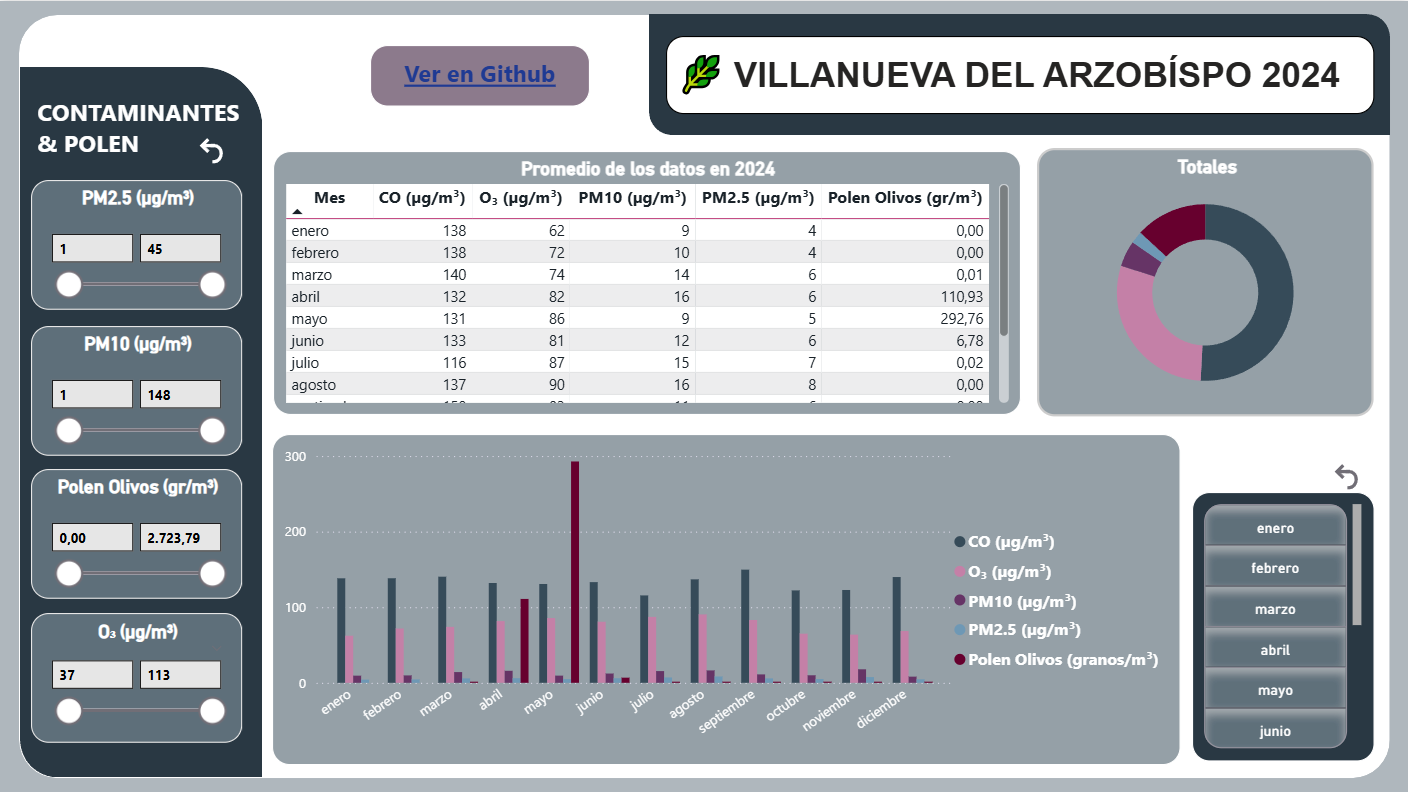
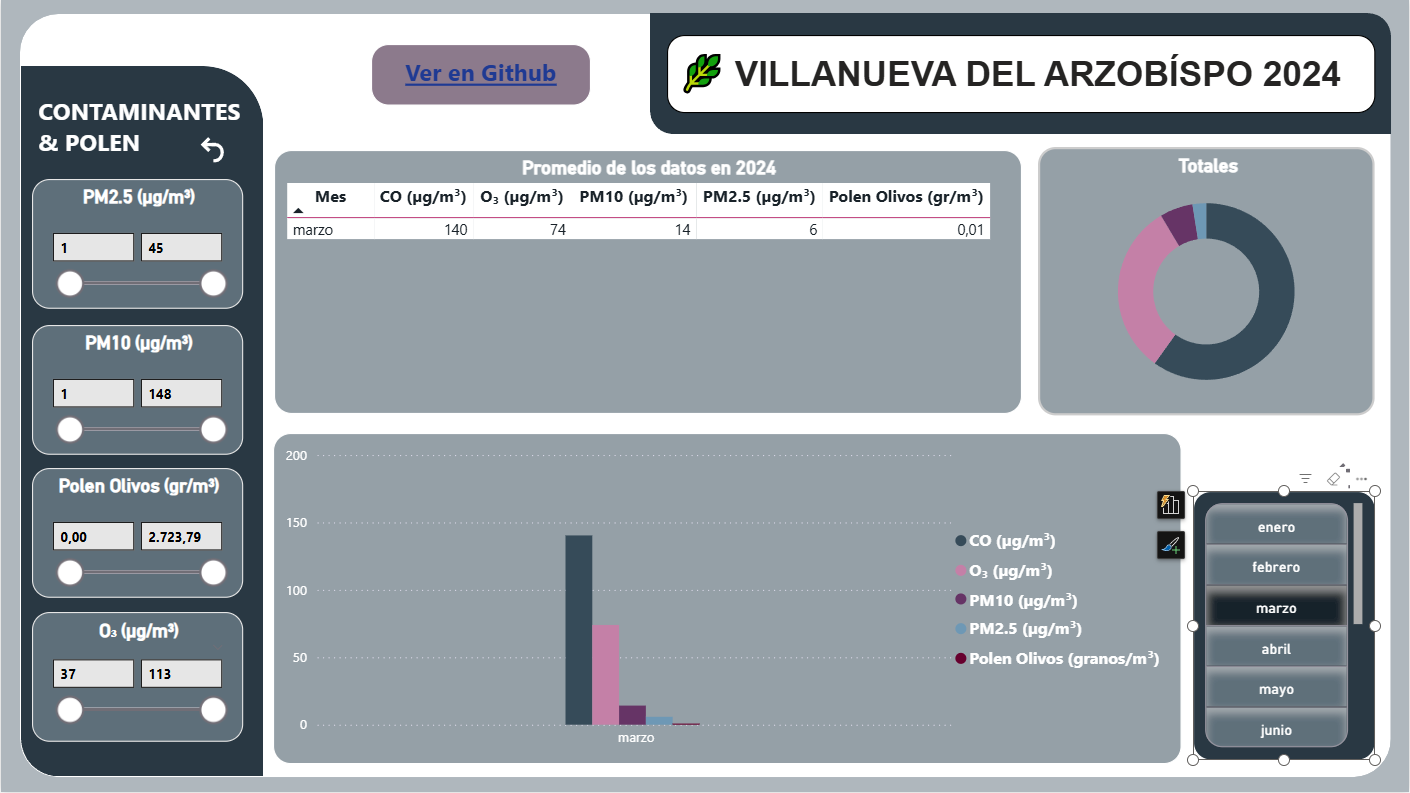
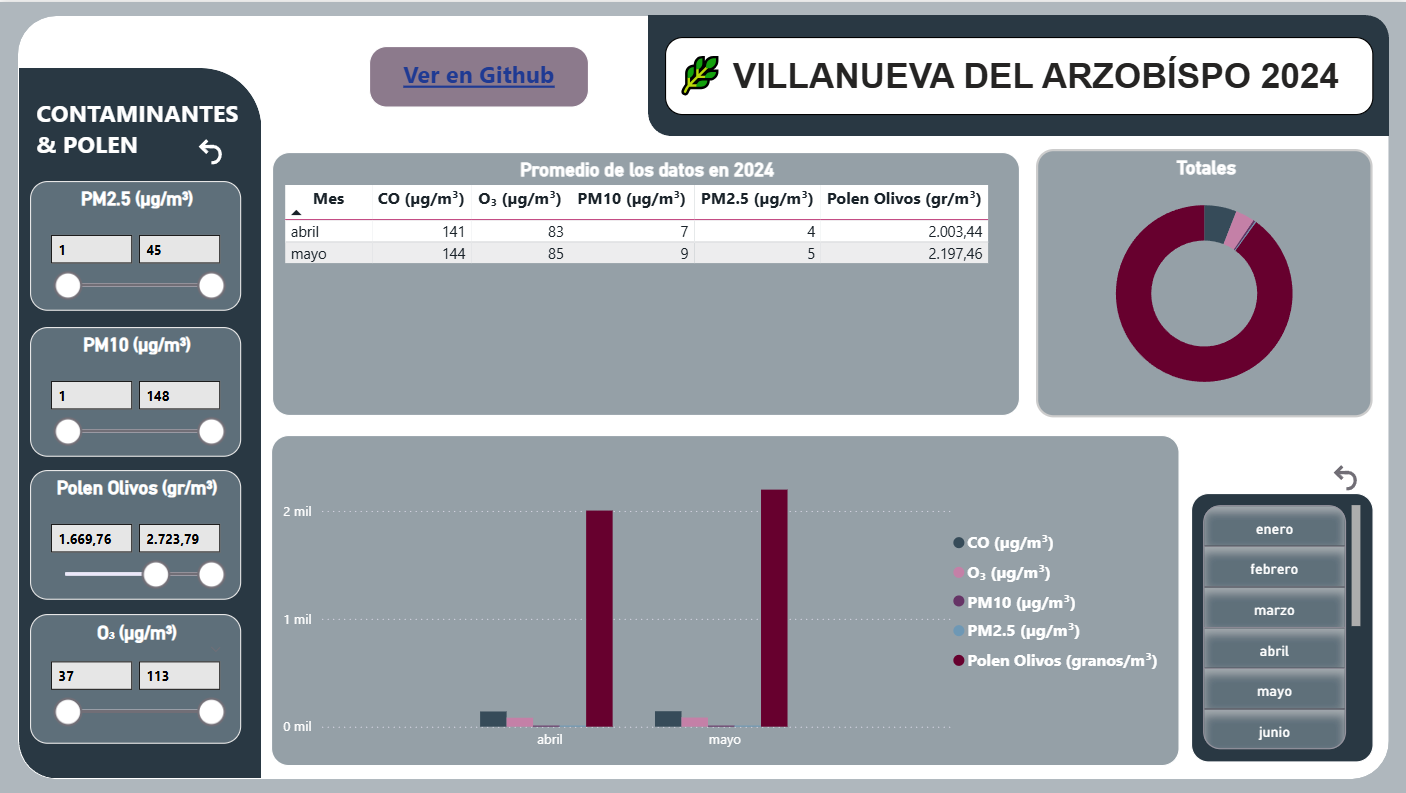
AireVis
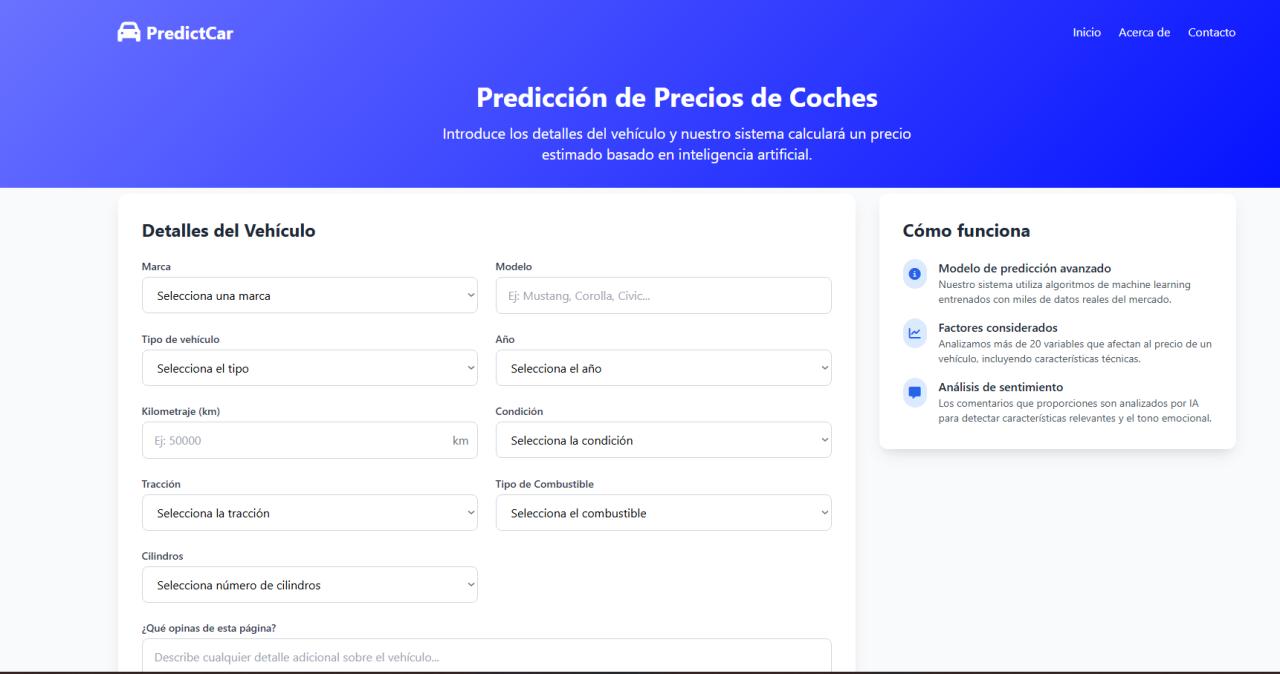
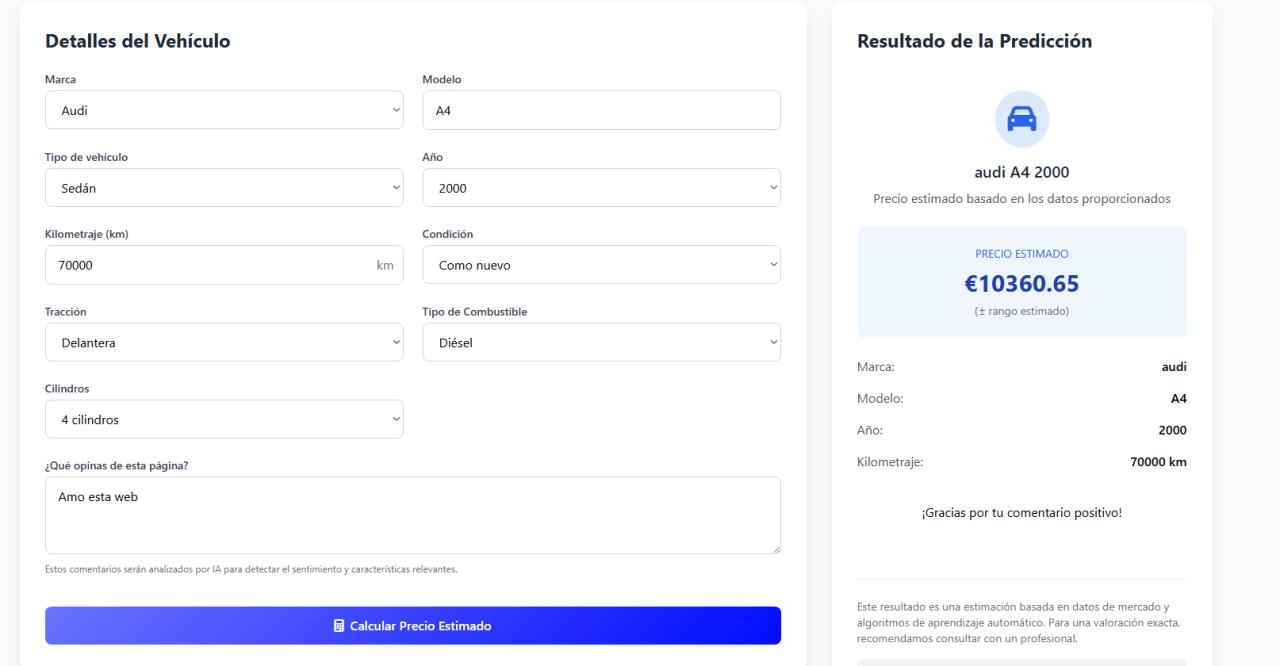
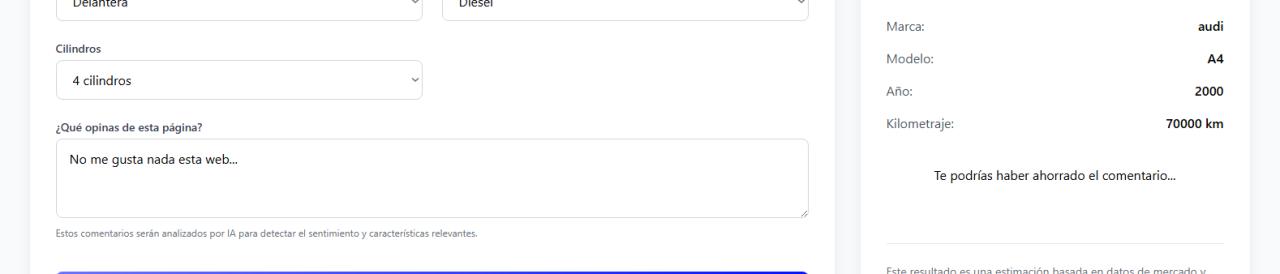
PredictCar
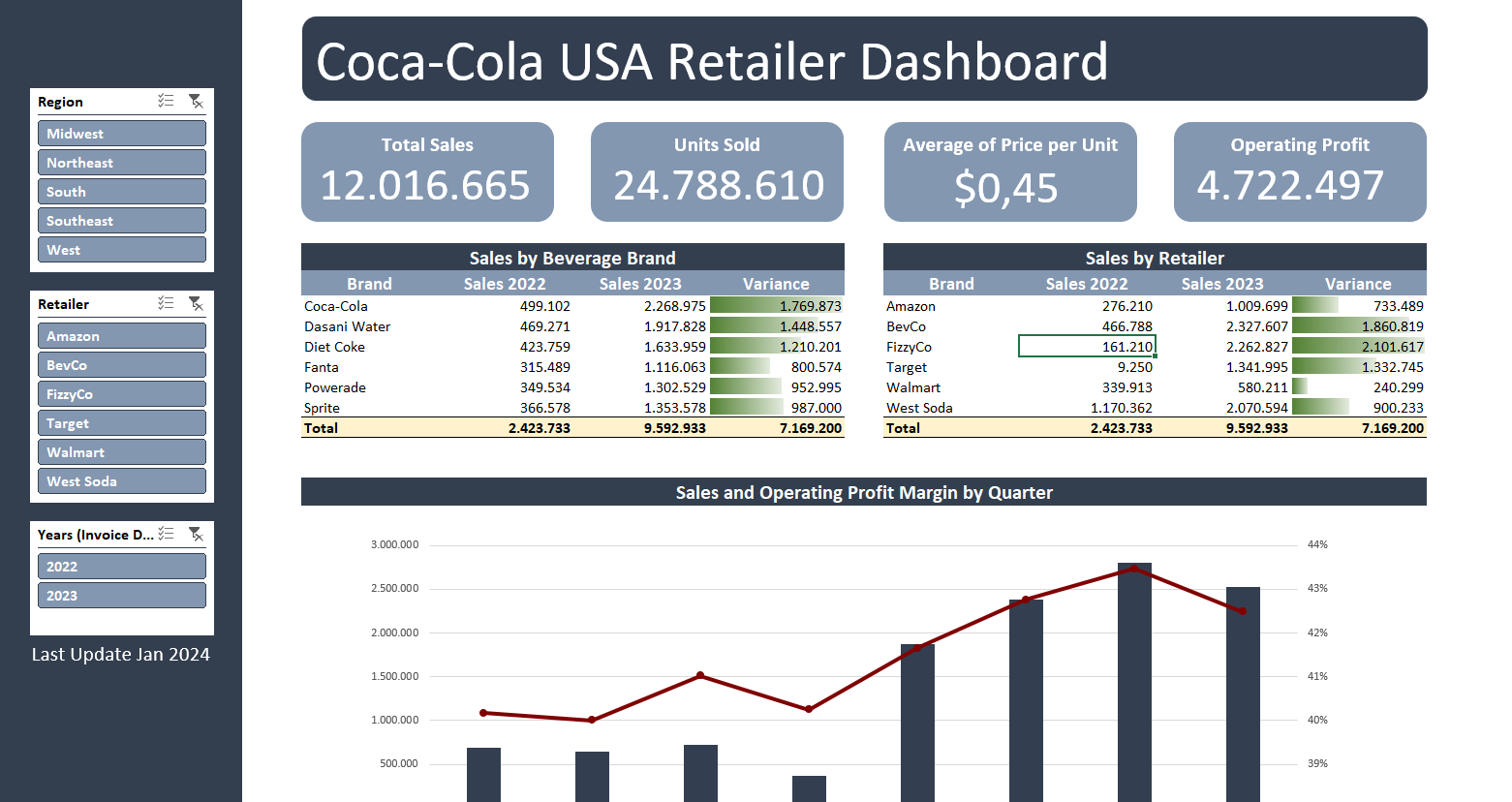
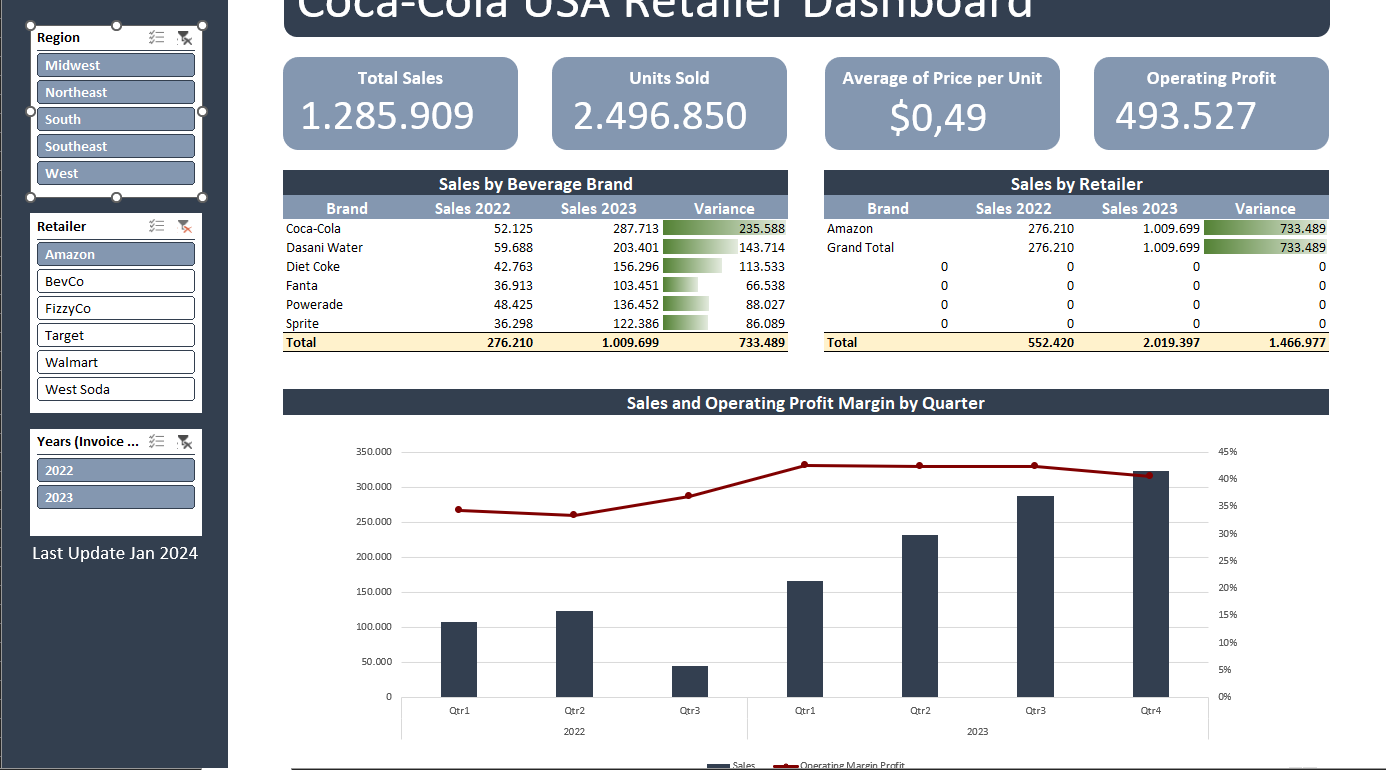
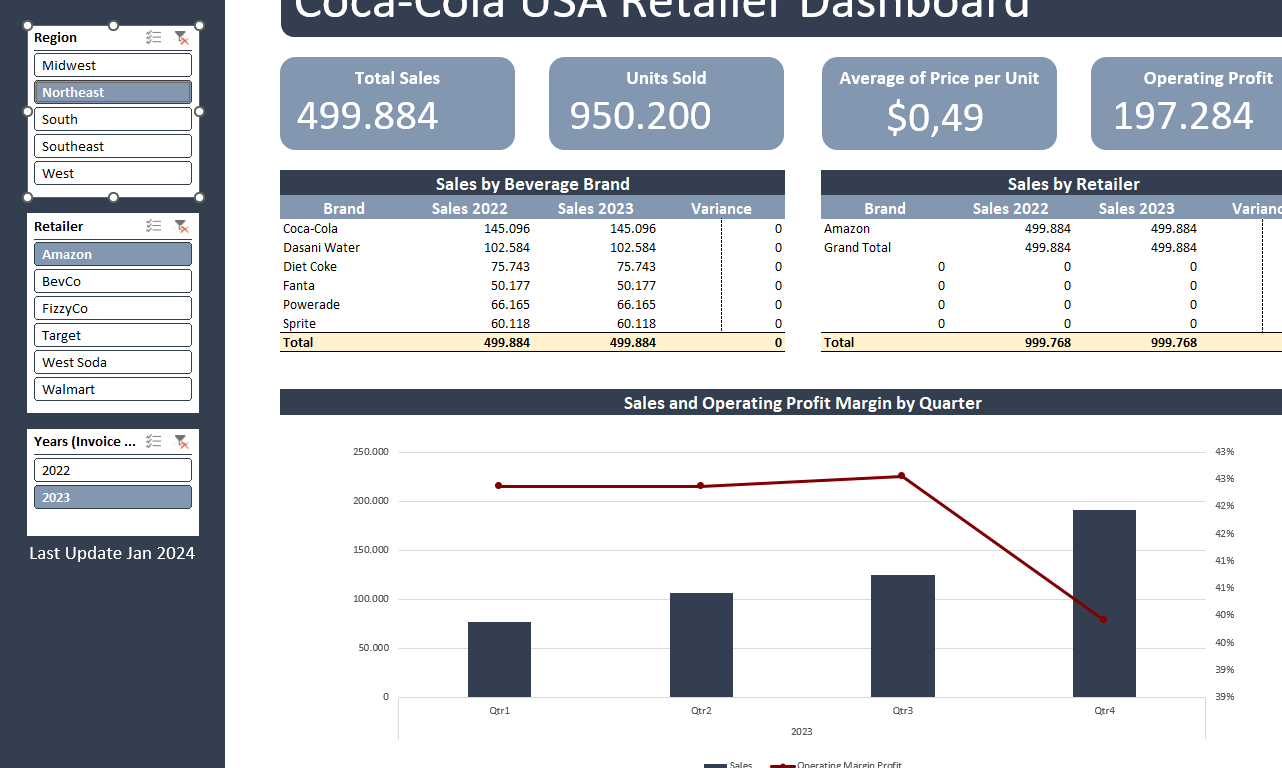
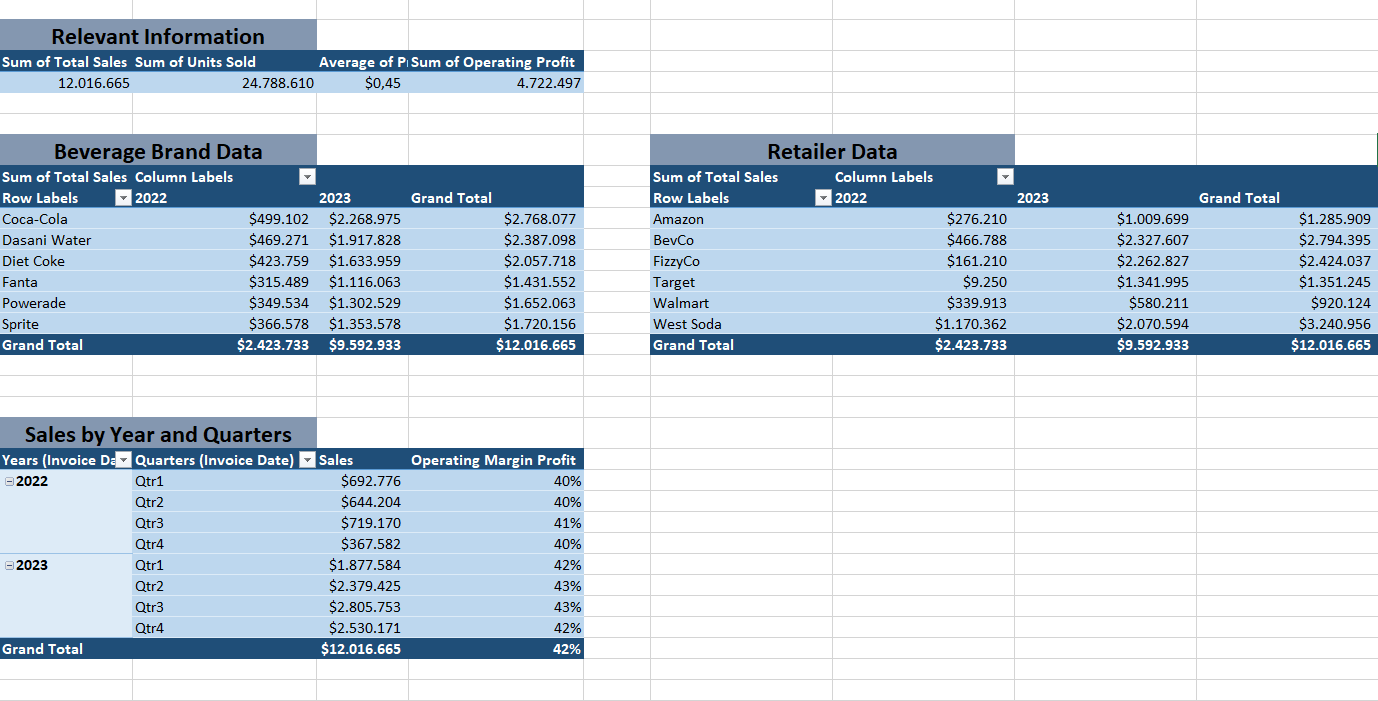
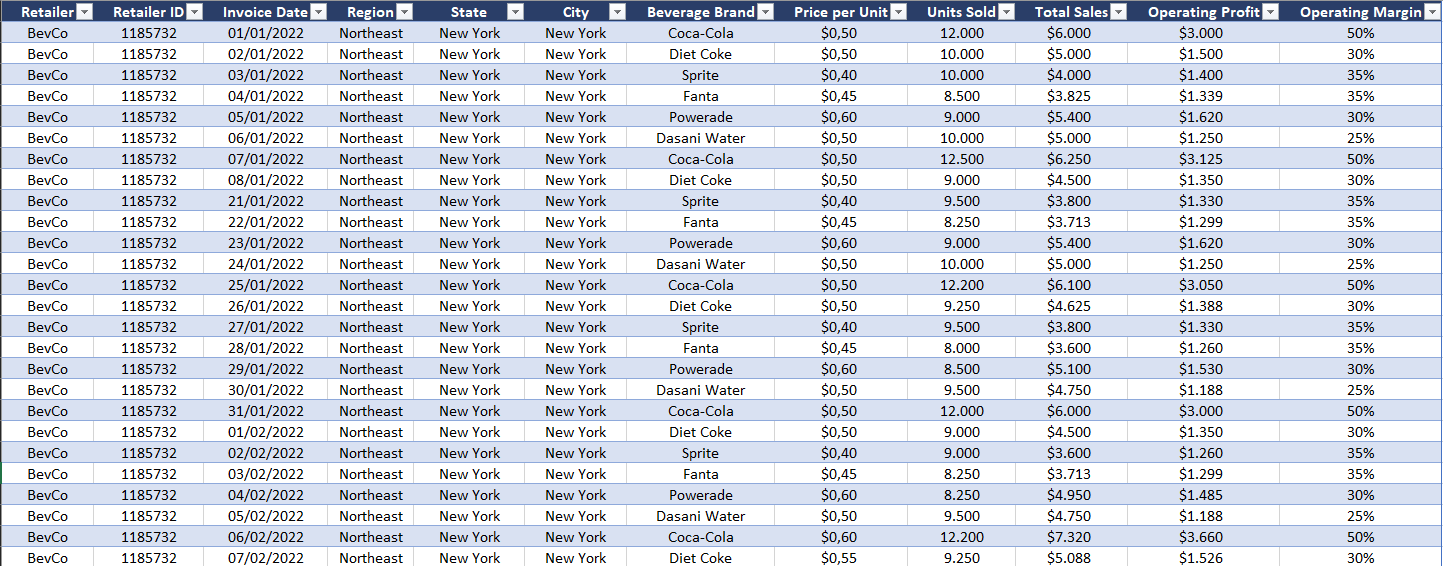
Retail Dashboard
Últimas certificaciones
Máster en Data Science e IA
Entidad: Evolve
Año: 2026
Nota media: En proceso
Máster en IA & BigData
Entidad: Digitech
Año: 2025
Nota media: 8
Grado superior en Desarrollo de Aplicaciones Web
Entidad: IES Mar del Alborán
Año: 2024
Nota media: 7